AI code quality metrics beyond DORA: the CTO's guide
Your board is asking for AI ROI numbers. Your traditional DORA metrics cannot produce them. Here is why and what a credible measurement framework looks like instead.
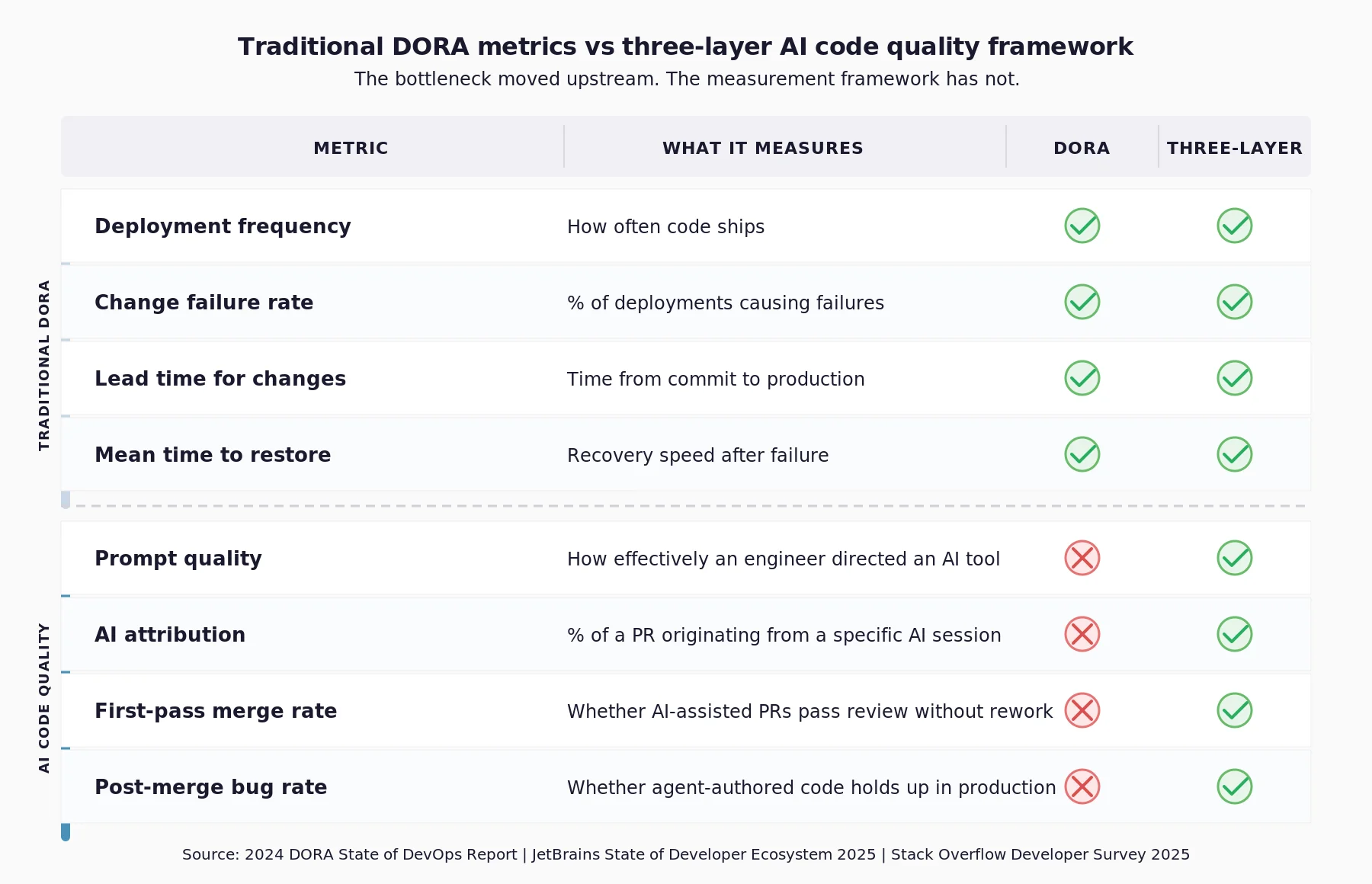
AI code quality metrics measure three things: how effectively an engineer directed an AI tool, including model selection, context provision, and prompt specification; how much of that session's code entered the codebase; and whether that output held up through review and into production, or was reverted or required rework.
DORA measures delivery speed. It cannot answer any of those three questions.
That gap is no longer theoretical. The JetBrains State of Developer Ecosystem 2025 surveyed 24,534 developers across 194 countries. 85% regularly use AI tools for coding. The measurement infrastructure to understand what those tools produce has not kept pace.
Why traditional DORA metrics are failing AI-first engineering teams
DORA's framework was built on one implicit assumption: humans wrote every line of code entering the pipeline.
That assumption is breaking down.
In Alphabet's Q1 2025 earnings call, Sundar Pichai confirmed that over 30% of code checked in involves engineers accepting AI-suggested solutions. That figure was 25% just two quarters prior.
The Stack Overflow Developer Survey 2025 found that 84% of developers are already using or planning to use AI tools. AI is no longer a productivity aid at the margins. It is a primary author.
Deployment frequency rises when AI generates code faster than engineers can write it. That signals throughput. It does not signal quality. Traditional DORA metrics do not distinguish between the two, which means a team generating more PRs faster looks identical to a team generating better code faster.
The 2024 DORA report found that as AI adoption increased, delivery stability fell by an estimated 7.2%. Traditional DORA can detect that number. It cannot explain it.
That gap matters for any CTO presenting an AI ROI case to a board. Delivery frequency answers the wrong question. The board is asking whether AI investment produced reliable, reviewable code. Traditional DORA metrics have no answer to that question, and presenting them as if they do damages credibility.
The hidden bottleneck: code review capacity
Senior engineers now review pull requests they did not author and cannot easily contextualise.
The AI that produced the code explains nothing. No reasoning. No constraints. No architectural assumptions.
The result is a predictable pattern:
- Reviewers skim faster to keep up with PR volume
- PR discussions increase as context is missing
- Engineers request additional information before approving
- Review cycles lengthen, eroding the speed gains AI was supposed to provide
None of this appears in a traditional DORA dashboard.
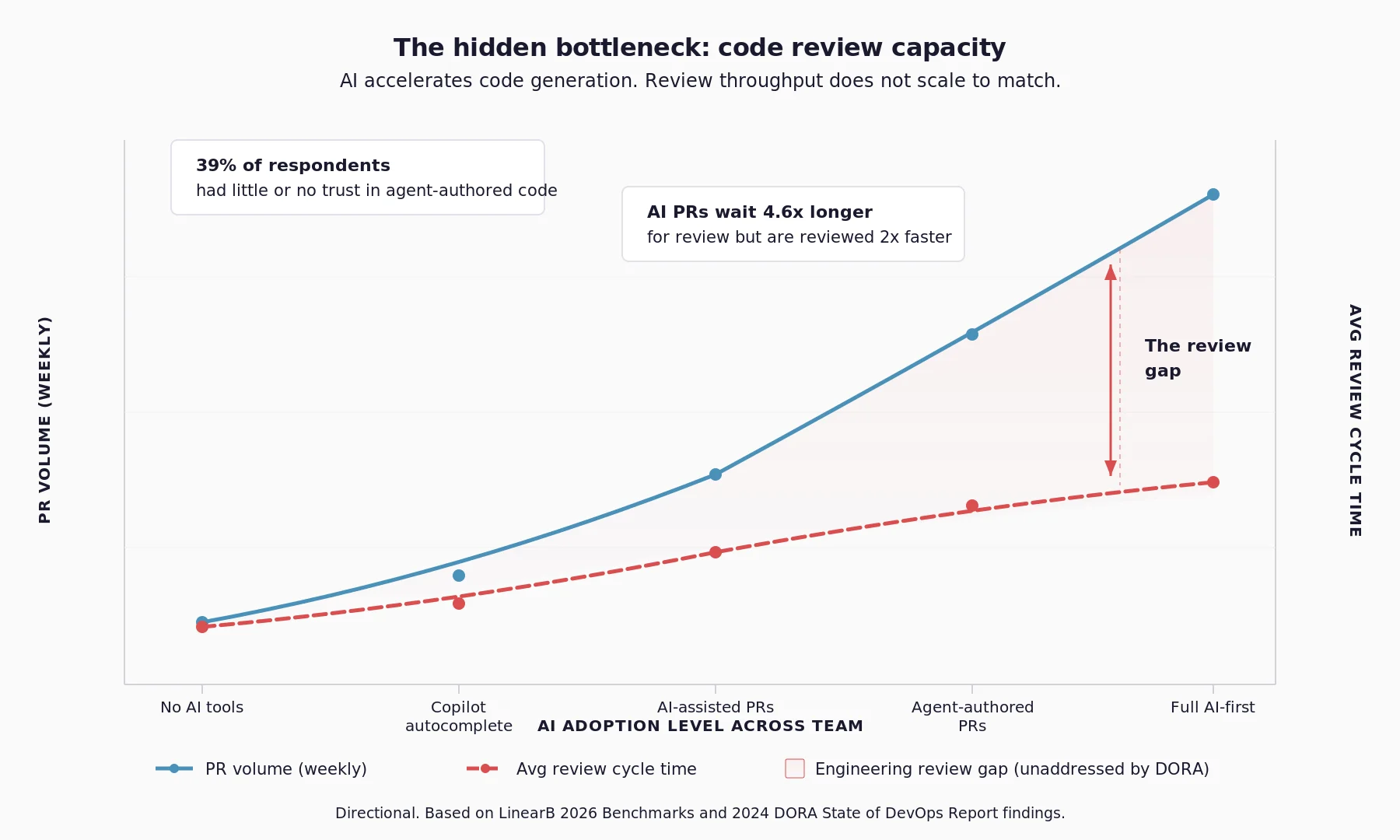
The 2024 DORA report found that 39% of respondents had little or no trust in agent-authored code. Engineers reviewing output they distrust take longer. Delivery stability falls. Traditional DORA records the damage. It does not locate the source.
The constraint is no longer writing code. It is reviewing code produced by AI systems. If your delivery stability has fallen as AI adoption has risen, the review queue is the most likely source. That is where instrumentation needs to start.
What do AI code quality metrics actually measure?
Three measurement dimensions are structurally absent from traditional DORA metrics. Each requires separate instrumentation.
1. AI input quality (input layer)
AI input quality measures how effectively an engineer used an AI coding tool before any code was produced. This includes:
- Whether the right model was selected for the task, a reasoning model for architectural decisions versus a fast completion model for boilerplate
- Whether the AI agent had sufficient repository context (file structure, dependencies, relevant modules)
- How well the agent's capabilities were used (tool access, multi-file editing, codebase search)
- How clearly the prompt specified intent, constraints, and edge cases
An engineer who selects the right model, feeds it relevant context, and prompts with a full error trace and explicit edge cases produces something reviewable on the first pass. One who defaults to the wrong model with no context produces something that consumes three review cycles before landing.
JetBrains' 2025 survey found that the most-cited concern about AI in software development was inconsistent output quality. Inconsistency at the output is almost always traceable to inconsistency at the input. Prompt quality is a leading indicator of code review burden.

2. AI attribution (the missing layer)
AI attribution determines what percentage of a PR originated from a specific AI session.
It is the layer that does not exist by default. A developer can generate an entire pull request inside an AI IDE and raise it manually. Version control records only a human commit.
Without instrumentation at the IDE level, no AI authorship is captured. Without attribution, connecting a session to a PR to a production outcome is structurally impossible. This is not a tooling preference. It is a blind spot built into how version control works.

3. Output quality (the closing layer)
Output quality closes the loop. The key indicators are:
- First-pass merge rate
- Post-merge bug rate within 30 days
- Revert rate
- PR size distribution relative to AI contribution level
Linking those signals back to AI contribution levels requires the attribution layer to already be in place. Without it, outcome data remains ambiguous. A partial view here is a marker, not a measurement.

How does AI session quality predict pull request outcomes?
The mechanism is direct. AI input quality predicts three things:
- Whether a reviewer can understand a PR's intent without reading the full diff
- Whether the AI had sufficient context to avoid generating API calls or schema fields that do not exist
- Whether edge cases were specified upfront or left for the reviewer to discover under pressure
The 2024 DORA data supports this direction. A 25% increase in AI adoption was associated with a 3.4% increase in code quality and a 3.1% increase in review speed. But only where teams had established clear guidelines for AI use. Where those guidelines were absent, the inverse was true.
Input discipline, model selection, context provision, and prompt specification, appears to be the variable that separates productive AI adoption from the kind that is associated with lower delivery stability.
Even with session-level attribution, confounding variables remain significant. Task complexity, reviewer experience, and codebase familiarity all affect review outcomes independently of AI input quality. A credible claim here requires stated confidence intervals, named confounds, and a methodology that can be reproduced.
Why AI leverage matters more than AI adoption
Tracking AI adoption is not enough. Seat licences and usage statistics do not tell you whether AI is improving engineering outcomes.
JetBrains' 2025 survey found that 66% of developers do not believe current metrics reflect their true contributions. That gap is now reaching the board table.
The question worth asking is not "How widely is AI being used?" It is "Does AI amplify the engineer's judgement, or merely accelerate code generation?" That distinction matters enormously to engineering budgets.
How to build a board-ready AI code quality framework
Boards are asking one question: did the AI coding investment produce measurable returns? Seat utilisation and deployment frequency cannot answer it.
A credible framework for measuring AI coding tool ROI has three components:
A metric that measures leverage, not adoption. Seat usage measures who logged in. Deployment frequency measures what shipped. Neither answers whether engineers are directing AI to produce trustworthy code. The question worth tracking is whether AI amplifies engineering judgement or merely accelerates code generation.
A methodology that holds up under scrutiny. A correlation between AI input quality and review cycle time, presented with stated confidence intervals and named confounding factors, will survive a CFO who asks how it was calculated. A productivity multiplier applied after the fact will not.
A joined dataset across the development lifecycle. The most technically difficult challenge is connecting AI interaction sessions to version control, to pull request workflows, to production outcomes in a single view. No mainstream tool currently provides that. Closing it requires instrumentation that starts at the AI input level, not at the PR.
The teams that build toward this now will have a structural advantage when the board asks next quarter.
What engineering leaders should do next
Traditional DORA metrics solved the right problem for a different era. With 85% of developers using AI tools and agent-authored code entering codebases at significant scale, the bottleneck has shifted. It is no longer producing code. It is applying human judgement to that code, at speed.
The teams that instrument AI code quality metrics now will have a defensible AI ROI story when the board asks. The rest will have a seat utilisation chart.
If your engineering team is running AI coding tools at scale and wants to understand how AI input quality connects to production outcomes, join Tetriz's Beta cohort today.