DORA metrics explained, and why they break at AI-first teams
DORA metrics are four engineering performance measures validated across thousands of organisations as the industry standard for benchmarking software delivery performance. In 2026, they remain necessary but no longer sufficient.
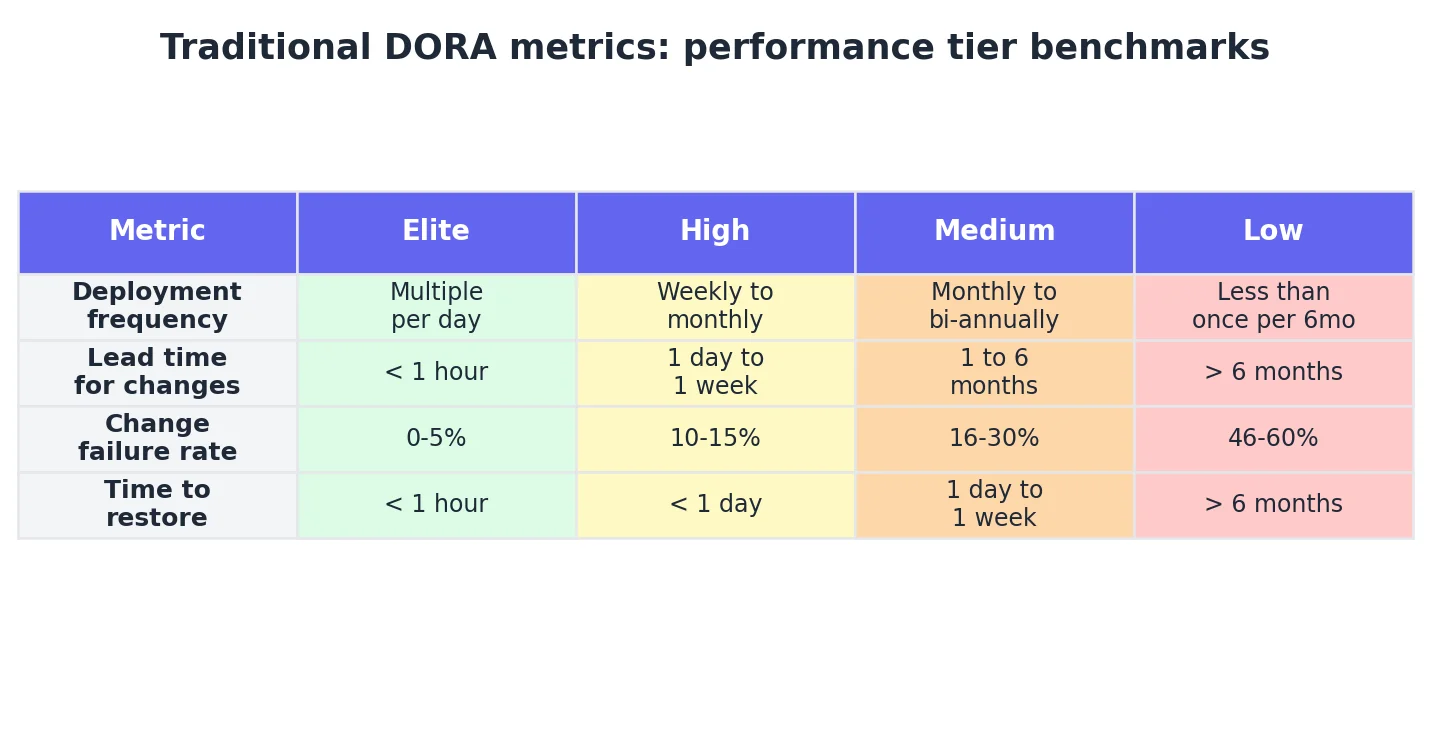
DORA metrics are four engineering performance measures validated across thousands of organisations as the industry standard for benchmarking software delivery performance:
- Deployment frequency
- Lead time for changes
- Change failure rate
- Time to restore service
In 2026, they remain necessary but no longer sufficient. At engineering teams where Cursor, Claude Code, or GitHub Copilot writes much of the code, DORA metrics still measure speed well, but they do not show the quality of the human guidance behind that speed.
The bottleneck moved. The metrics did not.
What are traditional DORA metrics?
Traditional DORA metrics are four software delivery performance measures developed by the DevOps Research and Assessment programme. These metrics originated from multi-year research that consistently separated high-performing teams from low-performing ones.
In 2023, a fifth metric, reliability, was added to capture operational stability. According to the 2024 DORA Report, over 39,000 professionals have contributed data across a decade of research. These numbers remain the industry standard; the question is not whether they matter, but what they miss.
Why do traditional DORA metrics break at AI-first engineering teams?
Traditional DORA metrics were designed before agent-authored code existed. Every validated correlation assumes that deployment frequency reflects human throughput and lead time reflects human pipeline efficiency. Neither assumption holds in 2026.
1. Deployment frequency inflation
A junior engineer using Cursor can produce a working PR in two hours for a task that previously took two days. Traditional DORA metrics record this as an "elite" performance signal, but the quality of direction provided to the AI tool remains invisible.
2. Lead time compression without quality signal
Agent-authored code compresses the generation stage. The new bottleneck is the code review queue. According to the 2024 DORA Report, while 75% of respondents use AI daily, 39% reported little to no trust in agent-authored code. Senior engineers now spend disproportionate time reviewing PRs without the original prompt context.
3. Change failure rate masking
If AI generates both the code and the unit tests based on a flawed understanding, the code may pass CI/CD but fail logically in production. The near-miss rate may climb even as the production failure rate appears steady, until senior reviewer capacity runs out.
The net result: A team can achieve "Elite" DORA status while accumulating massive review debt and systemic instability.
What do DORA metrics miss about agent-authored code quality?
Traditional DORA metrics miss three signals critical to AI-augmented teams:
- AI Input Quality: A measure of how effectively an engineer uses AI coding tools, whether the right model is selected for the task context, whether the AI agent has sufficient repository context, and whether the prompt clearly specifies the task.
- AI Attribution: Identifying what percentage of a PR was authored by AI. Without IDE-level instrumentation, GitHub sees only a human commit, making it impossible to distinguish between failures in human-written vs. agent-authored code.
- Reviewer Fatigue: Traditional metrics capture elapsed review time, but not review depth. AI adoption has correlated with a 3.1% increase in review speed, but faster is not better if the reviewer lacks the context of why the code was generated that way.
What should engineering leaders measure alongside traditional DORA?
The engineering metrics stack in 2026 requires three layers:
Layer 1: Traditional DORA (The Baseline)
- Metrics: Deployment Frequency, Lead Time, Change Failure Rate, Time to Restore.
- Purpose: Tracks the health of the delivery pipeline.
Layer 2: AI Adoption and Attribution (The Usage)
- Metrics: Seat usage, session frequency, AI contribution percentage.
- Purpose: Answers the CFO's question: who is actually using the tools we paid for?
Layer 3: AI Quality and Leverage (The ROI)
- Metrics: AI input quality scoring (model selection, repository context provision, prompt specificity), first-pass merge rate, post-merge bug rate for AI code.
- Key Indicator: Outcome Efficiency Score, a composite metric measuring how effectively an engineer directs AI to produce trustworthy code.
What traditional DORA metrics cannot tell your board
Traditional DORA metrics measure what shipped. They cannot measure whether the AI session was well-directed or whether the reviewer had the context to judge it. The fix is not to abandon DORA, but to instrument the layers it was never designed to capture.