What are DORA metrics? The engineering metric AI just broke
DORA metrics are four validated measures of software delivery performance. In 2026, 85% of developers regularly use AI coding tools and the four metrics were designed for a world where engineers wrote every line. That assumption no longer holds.
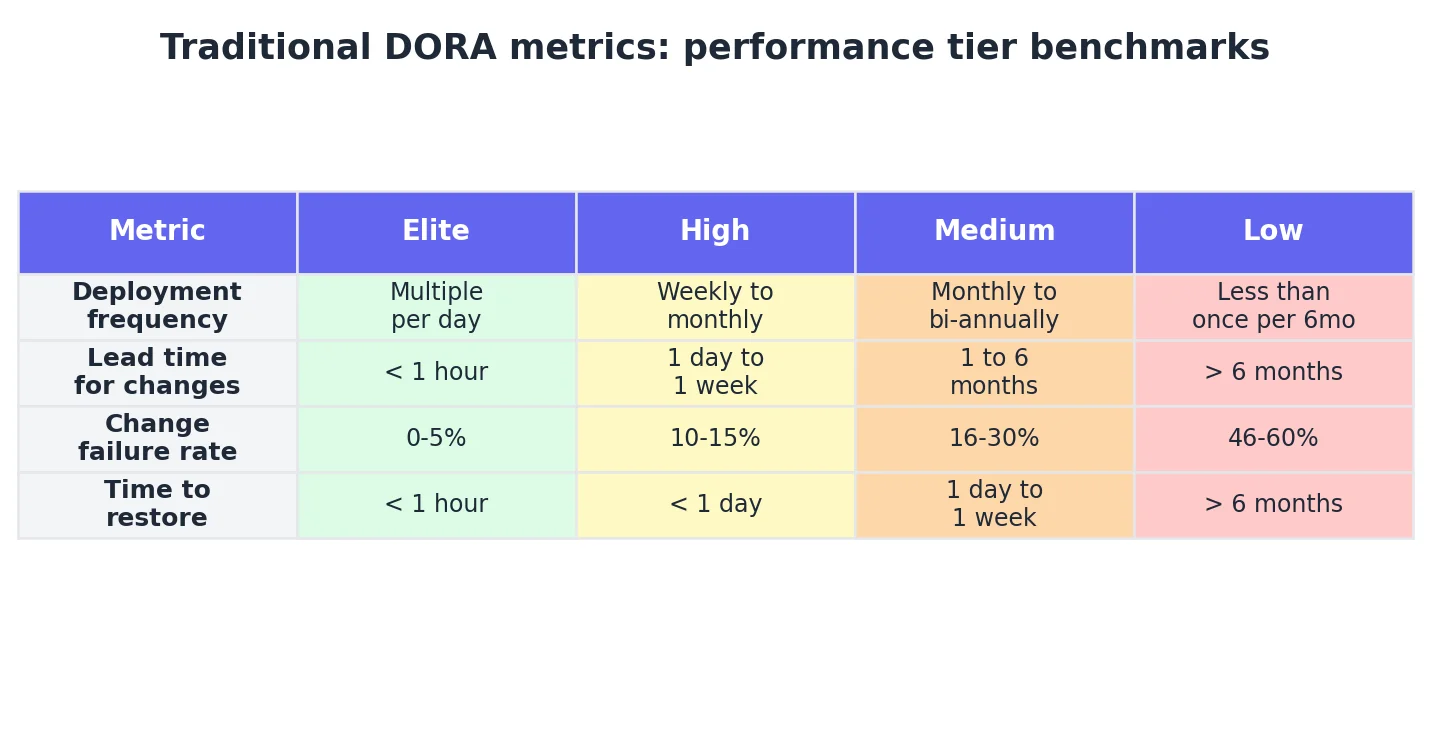
DORA metrics are four measures of software delivery performance:
- deployment frequency,
- lead time for changes,
- change failure rate, and
- time to restore service.
Validated across thousands of engineering organisations, these metrics define how boards and VPs benchmark engineering output.
In 2026, 85% of developers regularly use AI coding tools, and at companies like Alphabet, over 30% of checked-in code involves engineers accepting AI-suggested outputs.
The four DORA metrics were designed for a world where engineers wrote every line. That assumption no longer holds, and the measurement gaps are already showing up in review queues, incident postmortems, and board conversations your current dashboards cannot answer.
The DORA framework: origin and what it actually measures
The DevOps Research and Assessment programme began as academic research led by Dr. Nicole Forsgren, in collaboration with Jez Humble and Gene Kim.
Through factor analysis and structural equation modelling, the programme identified four metrics most consistently correlated with software delivery performance and organisational outcomes, including profitability and market share.
The findings were published in Accelerate: The Science of Lean Software and DevOps (2018), becoming the most-cited engineering performance research of the decade.
Google acquired the DORA programme in 2018, and the 2024 report added reliability as a fifth metric.
These metrics replaced anecdote-driven management with validated measurement. However, that clarity is now incomplete.
How AI coding tools broke DORA engineering metrics
The problem is not that AI makes teams faster, it is that DORA assumes human comprehension of every commit.
- Deployment Frequency Inflates: When AI generates code faster than humans, a team may appear "Elite" simply by volume. DORA does not capture whether that code is architecturally sound.
- Lead Time Bottlenecks: While generation is fast, the bottleneck moves to the review queue. According to LinearB's 2026 Benchmarks, AI-assisted PRs waited 4.6 times longer for review than human-written PRs, yet were reviewed twice as fast once started, a signal of reduced review depth.
- Change Failure Rate Blindness: Change failure rate can remain low even with logical errors because tests are often generated from the same flawed AI specification.
- Time to Restore Risks: Recovery time may increase if the engineer on call does not fully understand the agent-authored code they are rolling back.
The 2024 State of DevOps Report found that a 25% increase in AI adoption was associated with a 7.2% reduction in delivery stability scores. The risk is not the AI, it is the lack of instrumentation to verify it.

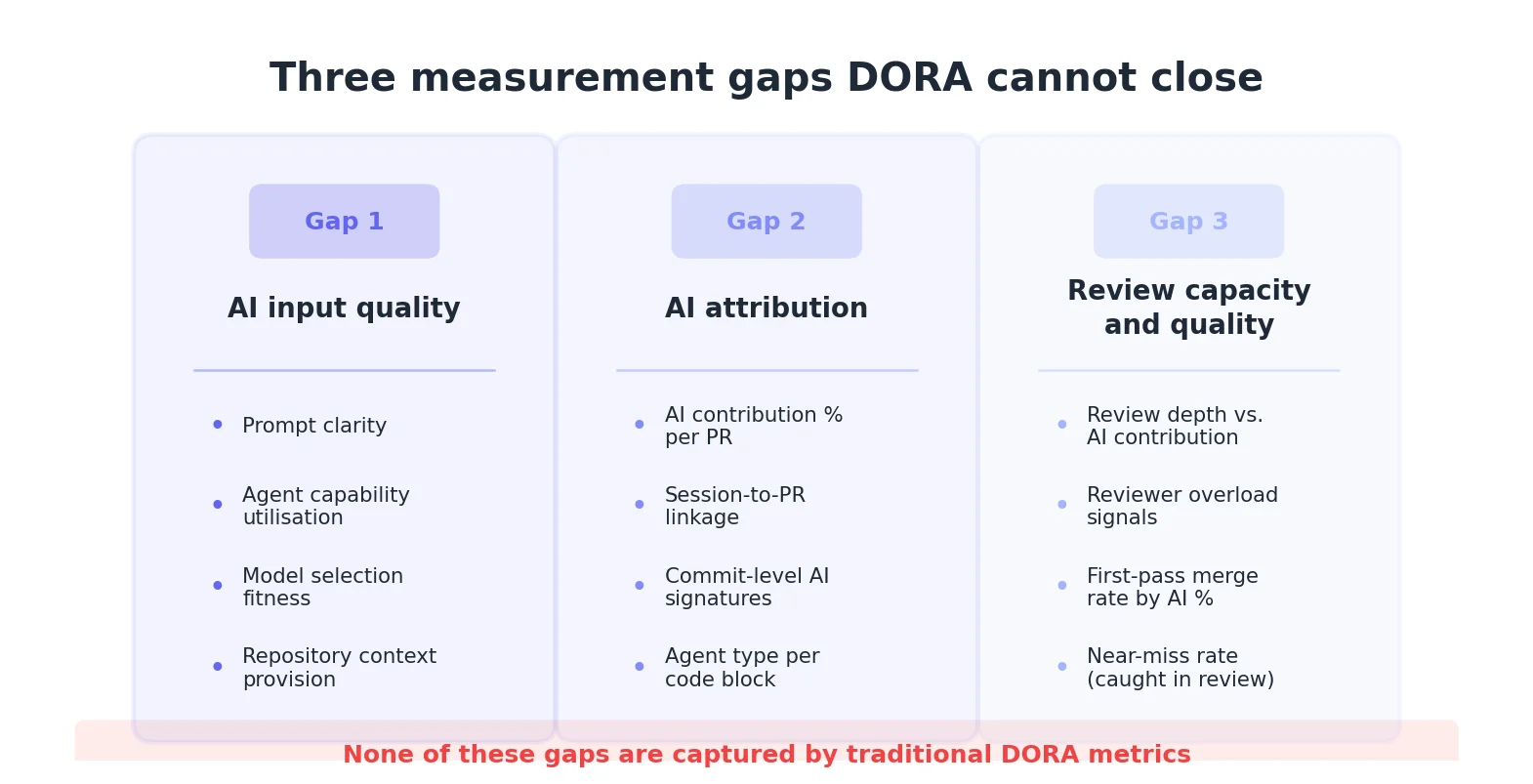
What are DORA metrics failing to capture in 2026?
Three specific measurement gaps have opened:
- Gap 1: AI Input Quality. The quality of the human direction, prompts, context, model selection. This is a leading indicator of code review burden.
- Gap 2: AI Attribution. GitHub has no native AI authorship concept. Without knowing which PRs are agent-authored, you cannot segment your failure rates.
- Gap 3: Review Capacity. DORA measures how long reviews take, but not how deeply they are conducted. With 39% of developers reporting low trust in agent-authored code, review queues are lengthening without signalling the underlying cause.
Beyond DORA: The Three-Layer Measurement Stack
Engineering managers should not replace DORA, they should layer it:
- Layer 1: Traditional DORA (Existing). Maintain the baseline for throughput and resilience.
- Layer 2: AI Adoption (The Middle). Track seat usage, session frequency, and contribution percentages.
- Layer 3: AI Quality and Leverage (The Gap). Measure AI input quality scoring and session-to-PR attribution.
Session-to-PR attribution data requires instrumentation at the moment sessions begin. You cannot build this dataset from historical commit data.
Tetriz solves exactly that. Join the early access Beta cohort now.
Are DORA metrics still worth measuring in 2026?
Yes. Traditional DORA metrics tell you how fast the pipeline runs. AI quality metrics tell you what is flowing through it. Without both, you can show speed to the board but cannot answer whether that speed is generating massive technical debt or rework.