The four categories of enterprise AI and why engineering needs its own
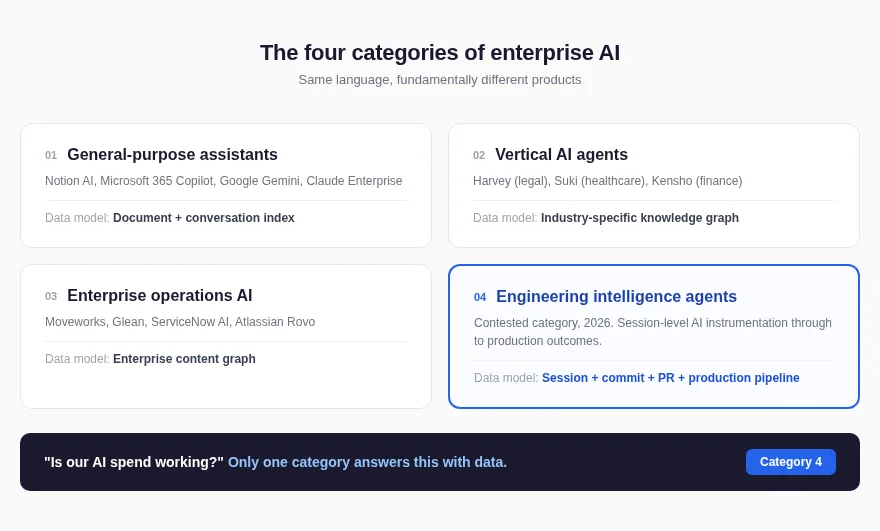
Enterprise AI categories split into four types, and most purchasing conversations conflate all of them. A CTO who cannot tell these apart will spend budget on a tool that delivers seat usage dashboards when what the board actually needs is session-level attribution.
Enterprise AI categories split into four types, and most purchasing conversations conflate all of them.
- General-purpose assistants draft documents.
- Vertical AI agents handle domain-specific workflows.
- Enterprise operations AI automates IT and HR processes.
- Engineering intelligence agents instrument the software development lifecycle from the AI coding session through to production.
A CTO who cannot tell these apart will spend budget on a tool that delivers seat usage dashboards when what the board actually needs is session-level attribution. This is a buying guide, not a taxonomy exercise.
What are the four enterprise AI categories?
The enterprise AI market in 2026 generates significant confusion. A CTO who cannot distinguish between these types will misspend budget and lose 6 to 12 months of evaluation time before discovering the tool cannot answer the question it was purchased to solve.
Why enterprise AI classification determines your board answer
Buying from the wrong category wastes more than a subscription fee, it wastes the time spent on integration and adoption. The purchasing mistake pattern follows a consistent shape:
- The ROI Gap: You buy a general-purpose assistant. You get better document search, but no answer for the board regarding AI coding tool productivity.
- The Quality Gap: You buy an analytics dashboard. You get traditional DORA charts, but no session-level data connecting AI sessions to code outcomes.
- The Review Gap: You buy an operations tool. You get better knowledge search, but no insight into why a specific PR took three days to review.
The most expensive mistake in 2026 is buying from the correct category's neighbour.
Enterprise operations AI looks like engineering intelligence in demos, but its instrumentation stops at the document layer. It never reaches the AI coding session.
How do engineering intelligence agents differ from Glean or Moveworks?
Engineering leaders increasingly ask why they cannot use Glean or Moveworks for their engineering AI use case. The answer is structural, not a matter of features.
The two categories differ across four dimensions that cannot be bridged by configuration or integration:
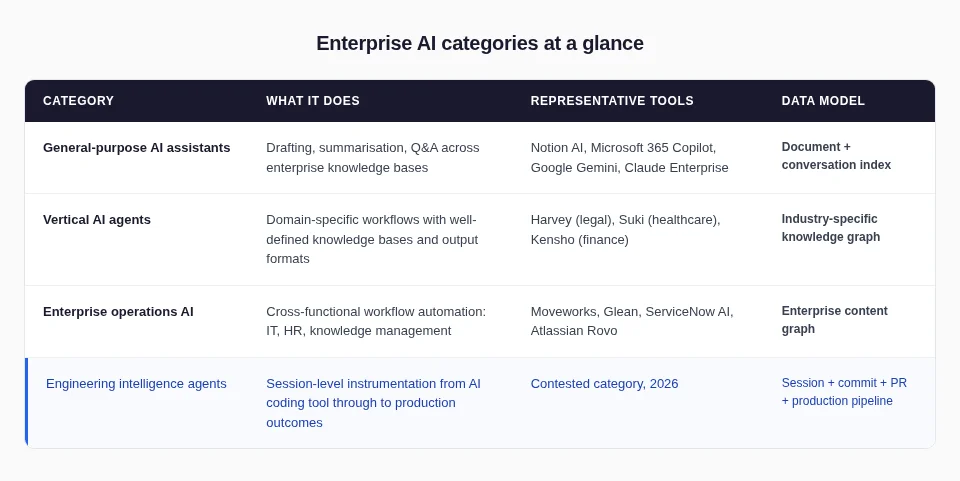
- Data Model: Glean and Moveworks index enterprise content, documents, Slack messages, Jira tickets, Confluence pages. An engineering intelligence agent's data model adds IDE session data, AI input quality scores, commit attribution data, and production outcome signals. AI input quality encompasses prompt quality, agent capability utilisation, LLM selection fitness, and repository context provision. Enterprise operations AI collects none of this.
- Instrumentation Layer: Glean instruments at the document layer. Moveworks instruments at the workflow layer. An engineering intelligence agent instruments at the session layer, reading Cursor, Claude Code, and Copilot sessions before the code is even committed. This upstream instrumentation is what enables session-to-PR attribution. No enterprise operations AI tool instruments at this layer.
- Output Type: Glean produces better search results. Moveworks produces automated workflow responses. An engineering intelligence agent produces AI input quality analysis, session-to-PR attribution data, and proactive engineering risk signals. The outputs differ because the questions differ.
- Access Control Model: Engineering data has a specific privacy topology, individual session data visible to the engineer first, team aggregates to the manager, organisation-wide trends to the CTO. Enterprise operations AI does not have this per-layer privacy architecture. For engineering intelligence, RBAC ensures session-level data does not flow upward before engineers choose to share it.
If you are evaluating enterprise AI tools and a vendor cannot explain where their instrumentation layer starts, that is the question that separates the categories.
The session-level attribution gap that defines category four
Traditional DORA metrics measure output exhaust: what shipped, how fast, how often. They cannot tell a CTO whether the AI coding sessions that produced that code were effective.
The 2024 DORA State of DevOps Report found that 75% of respondents use AI for at least one daily professional task, yet 39% report little to no trust in AI-generated code. Adoption is high. Confidence in what that adoption produces is not. That gap is what defines the engineering intelligence category and separates it from every other type of enterprise AI.
The gap has three layers that only engineering intelligence collects:
- AI Input Quality: Prompt quality, agent capability utilisation, and LLM selection fitness.
- AI Attribution: Identifying what percentage of a PR was AI-authored (since GitHub has no native concept of AI authorship).
- Output Quality: Connecting production outcomes, reverts, hotfixes, back to the original AI session.
General-purpose assistants, vertical AI agents, and enterprise operations platforms do not collect this data. The session-level attribution dataset requires instrumentation that starts at the AI coding session itself. That upstream starting point is the structural differentiator.

Atlassian's DX acquisition creates the closest convergence risk in this category. The combined entity (Jira, Bitbucket, Compass, DX, and Rovo) could approximate session-level attribution for Bitbucket users within 12 to 18 months if Atlassian integrates Rovo's AI with DX's intelligence layer. CTOs with Atlassian-heavy stacks should monitor this. CTOs on GitHub or GitLab sit outside Atlassian's data loop entirely, and the engineering intelligence question remains open.
What this means for your next enterprise AI purchase
The four-category enterprise AI classification is a buying guide. If the question you need to answer is "what is our AI spend producing in engineering?", general-purpose assistants, vertical AI agents, and enterprise operations platforms will not answer it.
The session-level attribution dataset that answers the board question requires instrumentation that starts upstream, at the AI coding session. That capability defines the engineering intelligence category and separates it from every other type of enterprise AI.
The category is being actively contested. Tetriz is building the engineering intelligence agent designed to close this gap, starting with AI input quality data that requires zero admin keys. Join the early access cohort today.