Prompt-to-PR attribution: what it is, why GitHub cannot track it, and how to evaluate it
Prompt-to-PR attribution connects the engineer's AI coding session to the pull request it produced. It links AI input quality, agent-authored code percentage, and review outcome in a single dataset. No engineering intelligence tool instruments at this layer today.
Prompt-to-PR attribution connects the engineer's AI coding session, the model they chose, the context they provided, and the prompt they wrote in Cursor, Claude Code, or Copilot, to the pull request that session produced.
It links AI input quality, agent-authored code percentage, and review outcome in a single dataset. No engineering intelligence tool instruments at this layer today.
Definition: Prompt-to-PR attribution is the method of linking an AI coding session to the specific pull request it produced and the review outcome of that PR. It starts upstream of the commit, at the prompt.
Your board is asking for AI ROI numbers. Seat usage cannot produce them. It shows who logged into Copilot; it does not show whether Copilot produced code that merged cleanly.
The dataset that answers the board's question starts at the prompt, not at the pull request. That dataset does not exist in any tool that instruments only at the commit layer.
What is Prompt-to-PR Attribution?
Prompt-to-PR attribution tracks the data dimensions that GitHub does not capture. It answers the question every engineering leader eventually asks: are your engineers directing AI effectively, and where can they extract even more value from these tools?
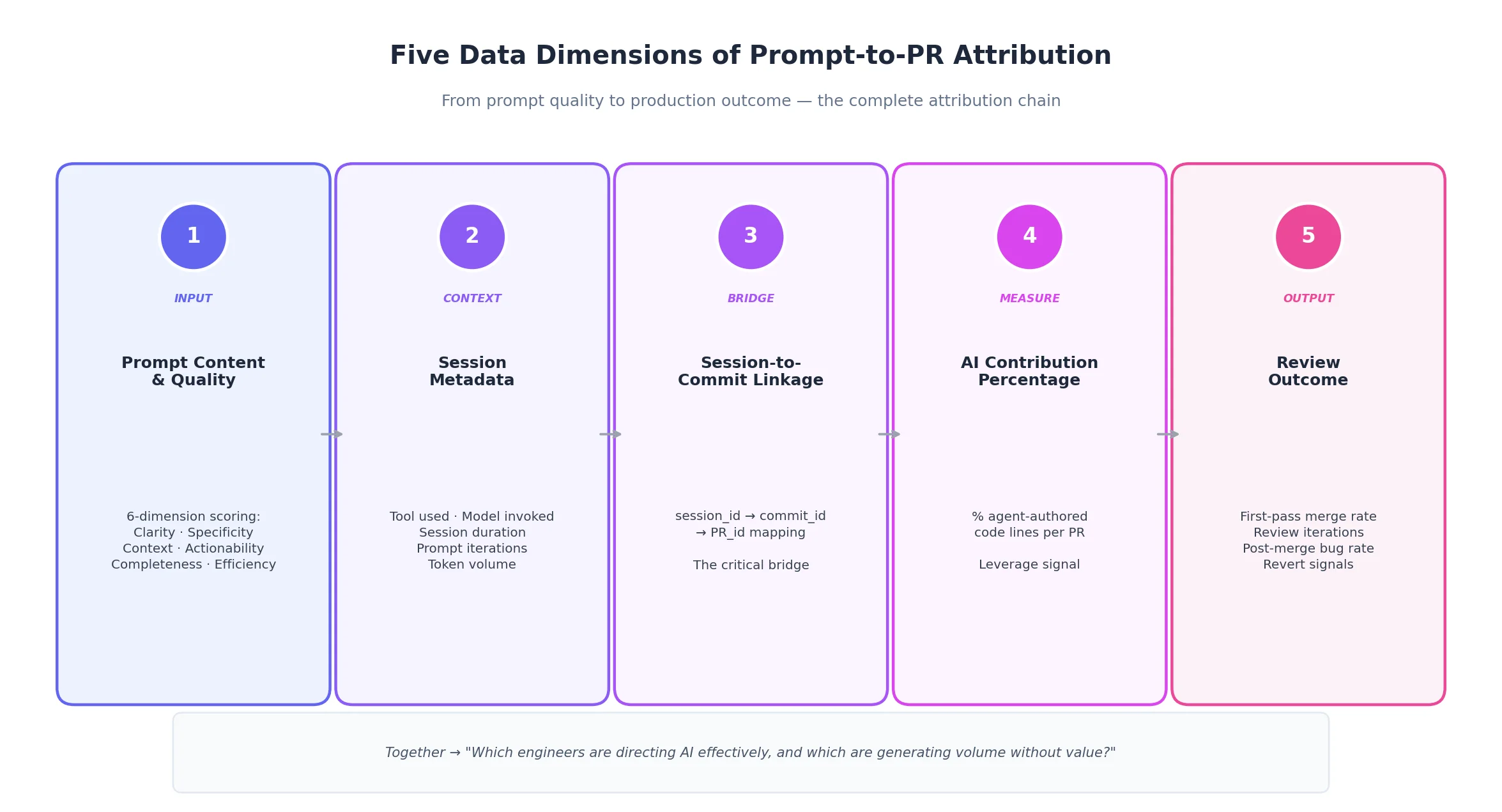
The concept requires five data layers working together:
- AI Input Quality: How effectively an engineer uses the AI coding agent, not just the prompt text, but whether the right model was selected for the task context, whether the agent had sufficient repository context, and how well the agent's capabilities were leveraged. Prompt quality is one dimension of input quality, not the whole picture.
- Session Metadata: Tool used, model invoked, duration, iterations, and token volume. This contextualises the quality score, for example, high iterations may indicate healthy refinement.
- Session-to-Commit Linkage: The mapping between a specific AI session and the commit it produced. This is the critical bridge to the review cycle and production outcome.
- AI Contribution Percentage: The proportion of agent-authored vs. human-written lines. This contextualises the relationship between AI input quality and review outcomes, higher AI contribution with strong input quality signals effective leverage.
- Review Outcome: First-pass merge rate, review iterations, and post-merge signals (bugs/reverts). This is the downstream consequence of AI input quality, the signal that closes the attribution loop.
Why GitHub Cannot Close the AI Code Attribution Gap
GitHub cannot track agent-authored code. Its data model records only a human email address for every commit. The prompt, the session, and the model remain invisible.
AI authorship did not exist when GitHub's data model was created. According to the GitHub 2024 Octoverse report, tools like Cursor and Claude Code have shifted a substantial share of code volume to agent-authored, but GitHub remains blind to the source.
The gap matters for three reasons
- AI ROI Attribution: Without identifying agent-authored code, you cannot attribute productivity gains. Seat usage tells you who logged in, not whether the tool actually worked.
- Quality Governance: You must know whether agent-authored code bypasses linting or security standards.
- Capability Assessment: Distinguishing between precise AI direction and blind pasting is vital for coaching and onboarding.
A note on privacy: Prompt-level data is sensitive. Any tool collecting this must make individual data IC-owned by default, with managers seeing only aggregates.
Where existing engineering intelligence tools stop
Several tools have advanced how engineering teams measure AI adoption, but each stops short of session-level attribution:
- Span detects AI-generated code with 95%+ accuracy using proprietary pattern recognition. It can tell you that 40% of a PR was agent-authored. It cannot tell you which session produced that code, what model was used, or whether the engineer provided sufficient context to the agent.
- Jellyfish tracks AI tool adoption across Cursor, Gemini, Sourcegraph, and Claude alongside Copilot through its expanded AI Impact module. It shows the CTO how many teams are using AI tools. It cannot connect a specific AI session to a specific PR outcome.
- LinearB offers the strongest workflow automation in the category through gitStream, and its Claude API integration enables natural language queries against dashboard metrics. Its AI Impact dashboard measures acceptance rates. It does not instrument at the session layer.
- DX (now part of Atlassian) built the research foundation for developer experience with the SPACE framework. For teams on Jira and Bitbucket, the Atlassian integration may eventually close the loop. For teams on GitHub, it cannot.
The structural gap is the same across all of them: they instrument at the commit or PR layer, not the session layer. Detection tells you what is there. Attribution tells you why it succeeded or failed.
What Does Solving Prompt-to-PR Attribution Require?
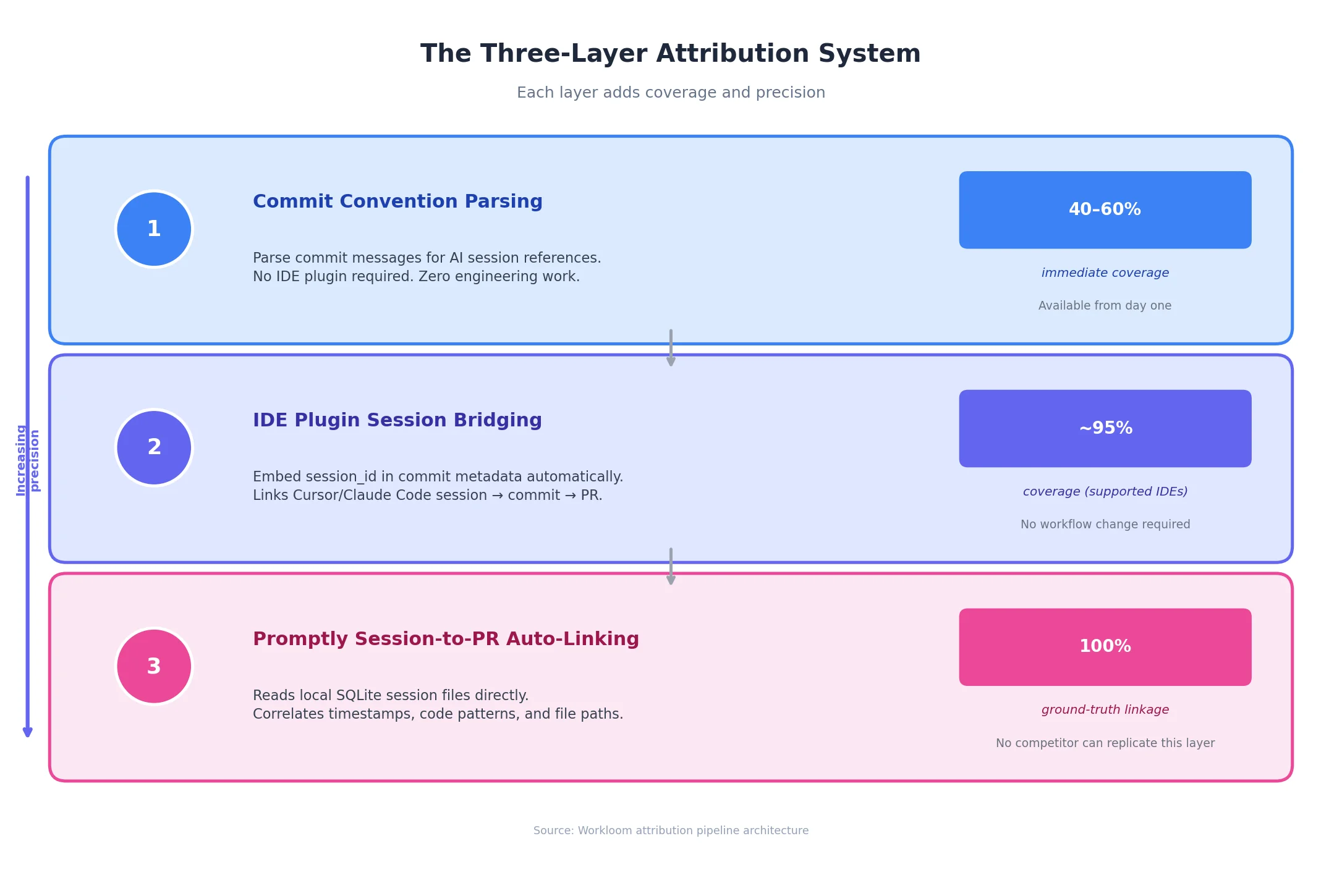
The core technical problem is simultaneous instrumentation at both the IDE and version control levels. This breaks into three layers:
- Commit-level signals: Parsing AI session references in commit messages. This offers partial coverage and depends entirely on team discipline.
- IDE-level instrumentation: An integration that embeds session identifiers in commit metadata, bridging the gap between the tool and version control without changing developer workflows.
- Local session capture: The ground truth. Reading session files from IDE telemetry and correlating them with repository data. This dataset cannot be constructed from GitHub's API alone.
Why Prompt-to-PR Attribution Matters for AI ROI
A CTO presenting to a board needs three answers:
- Activity: How much AI coding is happening?
- Quality: Is it producing good code?
- Attribution: Can outcomes be attributed to the investment?
Seat usage only answers the first. Prompt-to-PR attribution answers all three by providing named causal pathways. Session-level attribution resolves this information gap.
How to Evaluate Prompt-to-PR Attribution Software
Ask these three questions to determine whether a vendor is measuring forward from the prompt or backward from the PR:
- Where does your instrumentation start? If the answer is GitHub webhooks or Jira APIs, they have output exhaust, not session-level data. Tools like Jellyfish and LinearB start here. Span starts at code pattern detection. None start at the session.
- Can you connect a specific session to a specific PR? Span can tell you a PR contains AI-generated code. Jellyfish can tell you the team uses Cursor. Neither can tell you which Cursor session produced which PR, or whether the engineer used the right model for the task. That is the attribution gap.
- How do you handle the privacy model? This must be a structural design choice. IC-owned data by default is not just a policy promise, it is an architectural constraint.
Where to Start
Tetriz is building the dataset that resolves the attribution gap from the prompt layer forward. The Beta cohort is forming now. Sign up today.